O terceiro experimento pode ser visto no notebook 02-generate-new-sprite.ipynb.
O objetivo foi de treinar uma DCGAN no conjunto de dados TinyHero para gerar novas imagens de personagens
em pixel art nessas $4$ direções.
A rede generativa adversarial convolucional profunda (DCGAN) é dividida em uma rede geradora e outra discriminativa
que competem e evoluem em prol de possibilitar que a geradora consiga produzir imagens semelhantes às do treinamento.
Ambas redes foram relativamente rasas, com ~3 camadas e foram treinadas ao longo de $250$ épocas. Os resultados
não foram muito satisfatórios, conforme pode ser visto no resultado final:

Do ponto de vista da competição entre gerador e discriminador, seus erros ao longo das épocas evoluíram da seguinte forma:
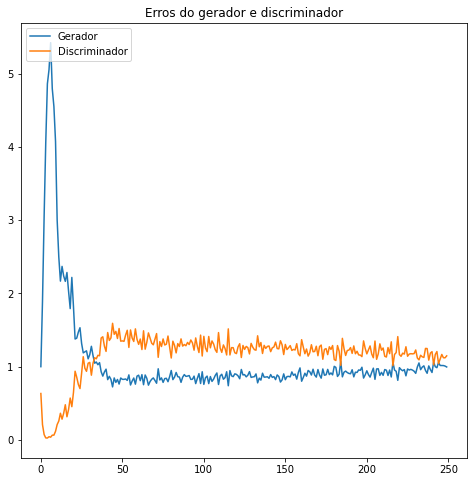
Tanto a arquitetura quanto hiperparâmetros de otimização e inicialização de pesos podem ser experimentados
e acredita-se que existam hipóteses de modelos que fornecerão resultados melhores.
Além disso, com a DCGAN vanilla não é possível definir qual classe de imagem se deseja gerar. Para tanto,
foram propostas as conditional GANs justamente para fornecer um controle de qual classe será gerada.